深入浅出计算机组成原理
入门
一、冯诺依曼体系结构
必备硬件:CPU、内存、主板、硬盘、输入输出设备,显卡。
可选硬件:独立显卡、机箱、风扇。
手机将CPU、内存、网络通信,乃至摄像头芯片,都封装到一个芯片,然后再嵌入到手机主板上。这种方式叫 SoC,也就是 System on a Chip(系统芯片)。
这样看起来,个人电脑和智能手机的硬件组成方式不太一样。可是,我们写智能手机上的 App,和写个人电脑的客户端应用似乎没有什么差别,因为,无论是个人电脑、服务器、智能手机,还是 Raspberry Pi 这样的微型卡片机,都遵循着同一个“计算机”的抽象概念。这其实就是,计算机祖师爷之一冯·诺依曼(John von Neumann)提出的冯·诺依曼体系结构(Von Neumann architecture),也叫存储程序计算机。
存储程序计算机
可编程、可存储。
计算器的本质是一个不可编程的计算机。
知识地图

二、什么是计算机的性能?
性能其实就是时间的倒数。
对于计算机的性能,我们需要有个标准来衡量。这个标准中主要有两个指标。
第一个是响应时间(Response time)或者叫执行时间(Execution time)。想要提升响应时间这个性能指标,你可以理解为让计算机“跑得更快”。
第二个是吞吐率(Throughput)或者带宽(Bandwidth),想要提升这个指标,你可以理解为让计算机“搬得更多”。
性能 = 1/ 响应时间
程序的 CPU 执行时间 =CPU 时钟周期数×时钟周期时间
CPU的主频数,就是一秒钟能执行多少条指令。这个 2.8GHz,我们可以先粗浅地认为,CPU 在 1 秒时间内,可以执行的简单指令的数量是 2.8G 条。
更准确的描述是CPU的钟表能识别出来的最小时间间隔。而在 CPU 内部,和我们平时戴的电子石英表类似,有一个叫晶体振荡器(Oscillator Crystal)的东西,简称为晶振。我们把晶振当成 CPU 内部的电子表来使用。晶振带来的每一次“滴答”,就是时钟周期时间。
超频就是将CPU内部的时钟调快了。
程序的 CPU 执行时间 =CPU 时钟周期数×时钟周期时间
不同指令的周期数不同,加法比乘法需要的时钟周期数更少
我们可以把自己想象成一个 CPU,坐在那里写程序。
计算机主频就好像是你的打字速度,打字越快,你自然可以多写一点程序。
CPI 相当于你在写程序的时候,熟悉各种快捷键,越是打同样的内容,需要敲击键盘的次数就越少。
指令数相当于你的程序设计得够合理,同样的程序要写的代码行数就少。
如果三者皆能实现,你自然可以很快地写出一个优秀的程序,你的“性能”从外面来看就是好的。
CPU的主频真的和性能直接挂钩吗?
早期工程师们想要提升CPU的性能,会盲目地提升主频,因为修改指令集和指令实现显然没有增加几个晶体管来得简单。
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
那么,为了要提升性能,我们需要不断地增加晶体管数量。同样的面积下,我们想要多放一点晶体管,就要把晶体管造得小一点。这个就是平时我们所说的提升“制程”。
CPU的电压低了,散热才容易跟得上。
并行优化,理解阿姆达尔定律
CPU的多核是将任务拆分成多个核心进行并行计算,但总有任务是无法并行计算的,并且最后还是需要汇总到一起的。
优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间
提升性能
如今提升CPU核心数,或者并行运算,又或是提升主频,都会遇到瓶颈。
-
加速运算:矩阵和向量运算用GPU来代替CPU。
-
拆分运算:将CPU执行的过程进行拆分。
-
通过预测提高性能。通过预先猜测下一步该干什么,而不是等上一步运行的结果,提前进行运算,也是让程序跑得更快一点的办法。
原理
一、机器码
通过objdump命令,可以将可执行程序反汇编成机器码。
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
int b = 2;
b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
a = a + b;
12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
15: 01 45 fc add DWORD PTR [rbp-0x4],eax
}
18: 5d pop rbp
19: c3 ret
常见的指令可以分成五大类。
第一类是算术类指令。我们的加减乘除,在 CPU 层面,都会变成一条条算术类指令。
第二类是数据传输类指令。给变量赋值、在内存里读写数据,用的都是数据传输类指令。
第三类是逻辑类指令。逻辑上的与或非,都是这一类指令。
第四类是条件分支类指令。日常我们写的“if/else”,其实都是条件分支类指令。
最后一类是无条件跳转指令。写一些大一点的程序,我们常常需要写一些函数或者方法。在调用函数的时候,其实就是发起了一个无条件跳转指令。
除了 C 这样的编译型的语言之外,不管是 Python 这样的解释型语言,还是 Java 这样使用虚拟机的语言,其实最终都是由不同形式的程序,把我们写好的代码,转换成 CPU 能够理解的机器码来执行的。
只是解释型语言,是通过解释器在程序运行的时候逐句翻译,而 Java 这样使用虚拟机的语言,则是由虚拟机对编译出来的中间代码进行解释,或者即时编译成为机器码来最终执行。
二、CPU 是如何执行指令的?
写好的代码变成了指令之后,是一条一条顺序执行的。
逻辑上,我们可以认为,CPU 其实就是由一堆寄存器组成的。而寄存器就是 CPU 内部,由多个触发器(Flip-Flop)或者锁存器(Latches)组成的简单电路。
CPU里面的寄存器
-
PC 寄存器(Program Counter Register),我们也叫指令地址寄存器(Instruction Address Register)。顾名思义,它就是用来存放下一条需要执行的计算机指令的内存地址。
-
指令寄存器(Instruction Register),用来存放当前正在执行的指令。
-
条件码寄存器(Status Register),用里面的一个一个标记位(Flag),存放 CPU 进行算术或者逻辑计算的结果。
除了这些特殊的寄存器,CPU 里面还有更多用来存储数据和内存地址的寄存器。这样的寄存器通常一类里面不止一个。我们通常根据存放的数据内容来给它们取名字,比如整数寄存器、浮点数寄存器、向量寄存器和地址寄存器等等。有些寄存器既可以存放数据,又能存放地址,我们就叫它通用寄存器。
if else其实就是goto
看汇编代码的话,会发现C语言的if语句被转换为了汇编的cmp和jne语句。
if (r == 0)
3b: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
3f: 75 09 jne 4a <main+0x4a>
{
a = 1;
41: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x1
48: eb 07 jmp 51 <main+0x51>
}
else
{
a = 2;
4a: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
51: b8 00 00 00 00 mov eax,0x0
}
jne 指令,是 jump if not equal 的意思,它会查看对应的零标志位。
如果为 0,会跳转到后面跟着的操作数 4a 的位置。这个 4a,对应这里汇编代码的行号,也就是上面设置的 else 条件里的第一条指令。当跳转发生的时候,PC 寄存器就不再是自增变成下一条指令的地址,而是被直接设置成这里的 4a 这个地址。
这个时候,CPU 再把 4a 地址里的指令加载到指令寄存器中来执行。
虽然我们可以用高级语言,可以用不同的语法,比如 if…else 这样的条件分支,或者 while/for 这样的循环方式,来实现不同的程序运行流程,但是回归到计算机可以识别的机器指令级别,其实都只是一个简单的地址跳转而已,也就是一个类似于 goto 的语句。
三、为什么会发生stack overflow?
我们在调用函数 A 之后,A 还可以调用函数 B,B 还能调用函数 C。这一层又一层的调用并没有数量上的限制。在所有函数调用返回之前,每一次调用的返回地址都要记录下来,但是我们 CPU 里的寄存器数量并不多。像我们一般使用的 Intel i7 CPU 只有 16 个 64 位寄存器,调用的层数一多就存不下了。
我们在内存里面开辟一段空间,用栈这个后进先出(LIFO,Last In First Out)的数据结构。
实际的程序栈布局,顶和底与我们的乒乓球桶相比是倒过来的。底在最上面,顶在最下面,这样的布局是因为栈底的内存地址是在一开始就固定的。而一层层压栈之后,栈顶的内存地址是在逐渐变小而不是变大。
如果函数调用层数太多,我们往栈里压入它存不下的内容,程序在执行的过程中就会遇到栈溢出的错误,这就是大名鼎鼎的“stack overflow”。
int a()
{
return a();
}
int main()
{
a();
return 0;
}
通过加入了程序栈,我们相当于在指令跳转的过程种,加入了一个“记忆”的功能,能在跳转去运行新的指令之后,再回到跳出去的位置,能够实现更加丰富和灵活的指令执行流程。这个也为我们在程序开发的过程中,提供了“函数”这样一个抽象,使得我们在软件开发的过程中,可以复用代码和指令,而不是只能简单粗暴地复制、粘贴代码和指令。
四、ELF和静态链接
“C 语言代码 - 汇编代码 - 机器码” 这个过程,在我们的计算机上进行的时候是由两部分组成的。
第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。在这三个阶段完成之后,我们就生成了一个可执行文件。第二部分,我们通过装载器(Loader)把可执行文件装载(Load)到内存中。CPU 从内存中读取指令和数据,来开始真正执行程序。
ELF
在 Linux 下,可执行文件和目标文件所使用的都是一种叫 ELF(Execuatable and Linkable File Format)的文件格式,中文名字叫可执行与可链接文件格式。
ELF 文件格式把各种信息,分成一个一个的 Section 保存起来。ELF 有一个基本的文件头(File Header),用来表示这个文件的基本属性,比如是否是可执行文件,对应的 CPU、操作系统等等。除了这些基本属性之外,大部分程序还有这么一些 Section:
-
首先是.text Section,也叫作代码段或者指令段(Code Section),用来保存程序的代码和指令;
-
接着是.data Section,也叫作数据段(Data Section),用来保存程序里面设置好的初始化数据信息;
-
然后就是.rel.text Secion,叫作重定位表(Relocation Table)。重定位表里,保留的是当前的文件里面,哪些跳转地址其实是我们不知道的。比如上面的 link_example.o 里面,我们在 main 函数里面调用了 add 和 printf 这两个函数,但是在链接发生之前,我们并不知道该跳转到哪里,这些信息就会存储在重定位表里;
-
最后是.symtab Section,叫作符号表(Symbol Table)。符号表保留了我们所说的当前文件里面定义的函数名称和对应地址的地址簿。
链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。
最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。
五、内存处理
内存碎片
内存连续划分,在启动多个程序之后关掉了其中一个,这个时候内存的分配不是连续的,就会产生内存碎片的问题。
内存交换(Memory Swapping)
将内存写到硬盘上,再紧挨着之前划分的读取回来,这样就能够解决内存碎片的问题。
硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。
内存分页
由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,让整个机器被内存交换的过程给卡住。
$ getconf PAGE_SIZE看页的大小。
当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。我们的操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。
这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
六、程序内部共享
如果我们能够让同样功能的代码,在不同的程序里面,不需要各占一份内存空间,这个思路就引入一种新的链接方法,叫作动态链接(Dynamic Link)。
相应的,我们之前说的合并代码段的方法,就是静态链接(Static Link)。
在动态链接的过程中,我们想要“链接”的,不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库(Shared Libraries)。顾名思义,这里的共享库重在“共享“这两个字。
动态链接库必须是地址无关的,比如传个参数,然后返回个参数。
动态链接库可以起到节约内存的作用。
七、二进制编码
原码表示法
0代表正数,1代表负数,0011表示为3,1011为-3。缺点是0可以用两个原码表示,1000或者0000。
关于乱码
如果我们想要用 Unicode 编码记录一些文本,特别是一些遗留的老字符集内的文本,但是这些字符在 Unicode 中可能并不存在。于是,Unicode 会统一把这些字符记录为 U+FFFD 这个编码。
如果用 UTF-8 的格式存储下来,就是\xef\xbf\xbd。如果连续两个这样的字符放在一起,\xef\xbf\xbd\xef\xbf\xbd,这个时候,如果程序把这个字符,用 GB2312 的方式进行 decode,就会变成“锟斤拷”。这就好比我们用 GB2312 这本密码本,去解密别人用 UTF-8 加密的信息,自然没办法读出有用的信息。
因为如果你用了 Visual Studio 的调试器,默认使用 MBCS 字符集。“烫”在里面是由 0xCCCC 来表示的,而 0xCC 又恰好是未初始化的内存的赋值。于是,在读到没有赋值的内存地址或者变量的时候,电脑就开始大叫“烫烫烫”了。
八、 加法
半加器是一个一个与门和一个异或门的结合。
全加器是两个半加器的结合。
出于性能考虑,实际 CPU 里面使用的加法器,比起我们今天讲解的电路还有些差别,会更复杂一些。真实的加法器,使用的是一种叫作超前进位加法器的东西。
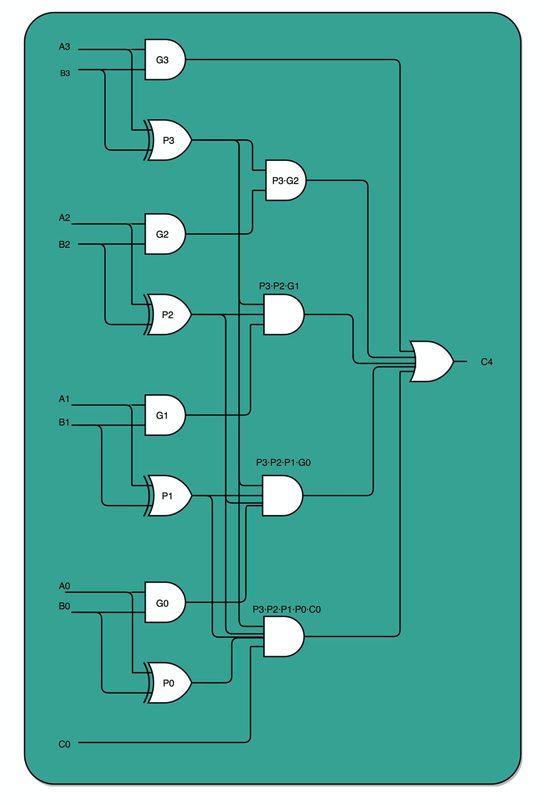
乘法是加法的延伸,相当于对加法做了循环。