InnoDB存储引擎相关知识
简介
InnoDB存储引擎支持B+树索引,哈希索引,全文索引和空间索引。后两者很少用到,但B+索引和哈希索引就很常见了。
前置知识 B+树
B+树是一种平衡查找树,其中B并不是指二叉树(Binary),而是平衡(Balance)。
MySQL的B+树索引可分为聚焦索引和非聚焦索引。
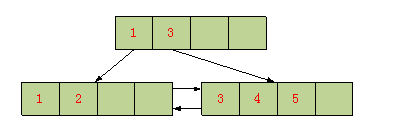
B+ 树是一种树数据结构,是一个n叉树,每个节点通常有多个孩子,一颗B+树包含根节点、内部节点和叶子节点。B+ 树通常用于数据库和操作系统的文件系统中。 B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。 B+ 树元素自底向上插入。
一个m阶的B树具有如下几个特征:
1.根结点至少有两个子女。
2.每个中间节点都至少包含ceil(m / 2)个孩子,最多有m个孩子。
3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m。
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
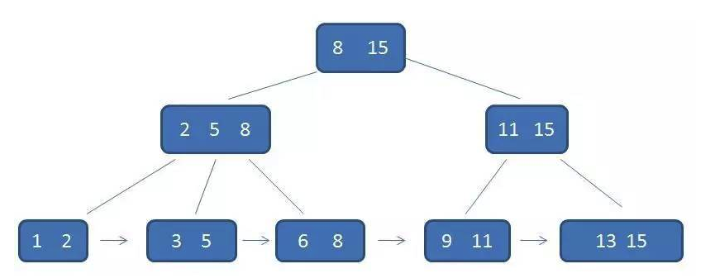
B+树的聚簇索引与非聚簇索引
B+树索引可以分为聚集索引和辅助索引,他们不同点是,聚集索引的行数据和主键B+树存储在一起,辅助索引只存储辅助键和主键。
1.聚集索引
聚集索引是按每张表的主键构造的一颗B+树,并且叶节点中存放着整张表的行记录数据,因此也让聚集索引的节点成为数据页,这个特性决定了索引组织表中数据也是索引的一部分。由于实际的数据页只能按照一颗B+树进行排序,所以每张表只能拥有一个聚集索引。查询优化器非常倾向于采用聚集索引,因为其直接存储行数据,所以主键的排序查询和范围查找速度非常快。
不是物理上的连续,而是逻辑上的,不过在刚开始时数据是顺序插入的所以是物理上的连续,随着数据增删,物理上不再连续。
2.辅助索引
辅助索引页级别不包含行的全部数据。叶节点除了包含键值以外,每个叶级别中的索引行中还包含了一个书签,该书签用来告诉InnoDB哪里可以找到与索引相对应的行数据。其中存的就是聚集索引的键。
辅助索引的存在并不影响数据在聚集索引的结构组织。InnoDB会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后通过主键索引找到一个完整的行记录。当然如果只是需要辅助索引的值和主键索引的值,那么只需要查找辅助索引就可以查询出索要的数据,就不用再去查主键索引了。
页的概念
页是InnoDB存储引擎管理数据库的最小磁盘单位。页类型为B-Tree node的页,存放的即是表中行的实际数据了。 InnoDB中的页大小为16KB,且不可以更改
InnoDB可以将一条记录中的某些数据存储在真正的数据页面之外,即作为行溢出数据。MySQL的varchar数据类型可以存放65535个字节,但实际只能存储65532个。同时InnoDB是B+树结构的,因此每个页中至少应该有两个行记录,否则失去了B+树的意义,变成了链表,所以一行记录最大长度的阈值是8098,如果大于这个值就会将其存到溢出行中。
查找B+树索引的流程
- 页介绍
首先通过B+树索引找到叶节点,再找到对应的数据页,然后将数据页加载到内存中,通过二分查找Page Directory中的槽,查找出一个粗略的目录,然后根据槽的指针指向链表中的行记录,之后在链表中依次查找。
需要注意的地方是,B+树索引不能找到具体的一条记录,而是只能找到对应的页。把页从磁盘装入到内存中,再通过Page Directory进行二分查找,同时此二分查找也可能找不到具体的行记录(有可能会找到),只是能找到一个接近的链表中的点,再从此点开始遍历链表进行查找。
- InnoDB数据页组成部分
File Header(文件头) Page Header(页头) Infimun + Supremum Records User Records(用户记录,即行记录) Free Space(空闲空间) Page Directory(页目录) File Trailer(文件结尾信息)
InnoDB存储引擎
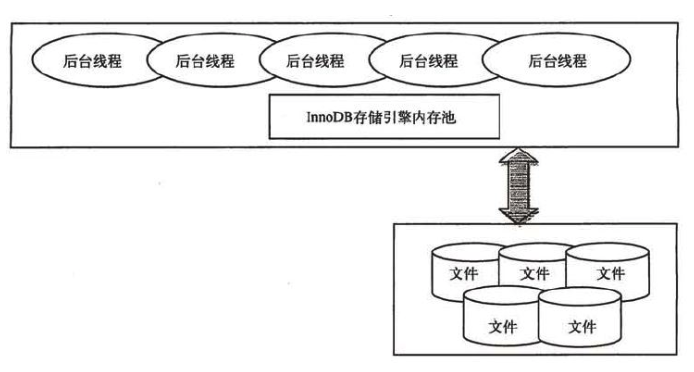
InnoDB存储引擎有多个内存块,这些内存块组成了一个大的内存池。后台线程主要负责刷新内存池中的数据、将已修改的数据刷新到磁盘等等。
InnoDB引擎同时支持ACID事务,以及支持外键。
InnoDB和MyISAM引擎的区别与优劣
区别:
-
1.InnoDB 支持事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
-
2.InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败;
-
3.InnoDB 是聚集索引,MyISAM 是非聚集索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。
因此,主键不应该过大,因为主键太大,其他索引也都会很大。而 MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
-
4.InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
-
5.InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。 这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一。
如何选择:
-
1.是否要支持事务,如果要请选择 InnoDB,如果不需要可以考虑 MyISAM;
-
2.如果表中绝大多数都只是读查询,可以考虑 MyISAM,如果既有读写也挺频繁,请使用InnoDB。
-
3.系统奔溃后,MyISAM恢复起来更困难,能否接受,不能接受就选 InnoDB;
-
4.MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的。