C++双向链表实现
双向链表的原理与特点
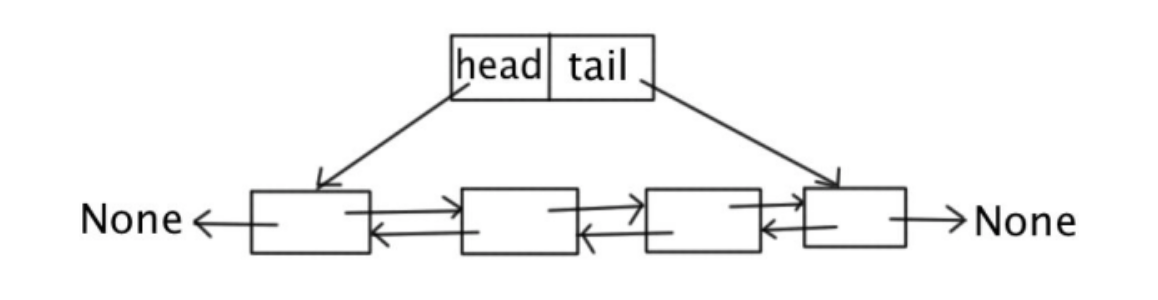
双链表相比单链表而言,有头结点和尾节点,而每个数据节点也有前后两个节点指针。
源码地址
具体实现及原理
1.类结构定义
class Node
{
public:
int data;
Node * last;
Node * next;
};
class DoubleNode
{
private:
Node * head; //头结点
Node * tail; //尾节点
};
定义了head和tail节点,以及每个数据节点的前后指针,最基本的双向链表。
2.构造函数
DoubleNode::DoubleNode()
{
head = nullptr;
tail = nullptr;
}
个人不想在构造函数new头尾节点,也没必要实现太复杂的操作,象征性的初始化即可。
3.析构函数
DoubleNode::~DoubleNode()
{
if(getsize()!=0)//空表就没必要调析构了
{
Node *ptemp = head;
Node *p;
while(ptemp!=nullptr&&ptemp->next!=nullptr)
{
p=ptemp;
ptemp=ptemp->next;
delete p;
p=nullptr;
}
}
}
注意空链表不能析构
4.求长度
int DoubleNode::getsize()
{
Node *temp = new Node;
temp = head;
int length=0;
if(temp==nullptr||temp->next==nullptr)
{
return length;
}
while(temp->next!=nullptr&&temp->next!=tail)
{
length++;
temp = temp->next;
}
return length;
}
5.判断是否为空
bool DoubleNode::isempty()
{
if(head == nullptr||head->next==nullptr)
{
return true;
}
else
{
return false;
}
}
其实和求长度有一点接近,长度为0那就应该是空表。
6.建表
void DoubleNode::create(int len)
{
if(len<=0)
{
cout<<"argu is illegal!"<<endl;
return;
}
head = new Node;
head->next = head->last = nullptr;//初始化
tail = head;//空链表头尾指针指向一个位置
for(int i=0;i<len;i++)
{
Node *pnew = new Node; //创建一个新的节点
cout<<"enter num"<<i+1<<" value"<<endl;
cin>>pnew->data; // 赋值
pnew->next = nullptr;
/*
* 借用尾节点的地址,因为新节点在尾节点的位置
* 所以last指针指向尾节点的位置
* 这样也不需要用temp指针去管理头结点的位置了
*/
pnew->last = tail;
tail->next = pnew; //为了让节点往后移动
tail = pnew;//tail就是每次循环的上一个新节点,每次让它变成新节点
}
Node *temp =new Node;
temp->next =nullptr;
temp->last = tail;
tail = temp;
}
在建表完成之后,其实尾节点是和最后一个元素的地址相同了,因此处理方式就是new一个新的节点,添加到链表的最后,将它作为尾节点。
7.前驱遍历
void DoubleNode::showhead()
{
Node * temp = head->next;
if(temp==nullptr)
{
cout<<"this list is empty"<<endl;
return;
}
//如果next指针指向尾节点,说明到最后了
while(temp!=nullptr&&temp!=tail)
{
cout<<temp->data<<endl;
temp=temp->next;
}
}
8.后驱遍历
void DoubleNode::showtail()
{
Node * temp = tail;
if(temp==nullptr)
{
cout<<"this list is empty"<<endl;
return;
}
while(temp->last!=nullptr&&temp->last != head)
{
temp=temp->last;
cout<<temp->data<<endl;
}
}
9.查找
int DoubleNode::get(int index)
{
int length = this->getsize();
if(length == 0)
{
cout<<"this is an empty list"<<endl;
return 0;
}
if(index>length||index<=0)
{
cout<<"illegal index value!"<<endl;
return 0;
}
if(index<=length/2)//前一半
{
Node * temp = head;
for(int i=0;i<index;i++)
{
temp = temp->next;
}
cout<<"search at head"<<endl;
return temp->data;
}
else//后一半
{
Node * temp =tail;
for(int i=0;i<length-index+1;i++)
{
temp = temp->last;
}
cout<<"search at tail"<<endl;
return temp->data;
}
}
部分借用二分查找的思想,如果节点的值是长度的前一半,就用前驱遍历,如果是后一半,就后驱遍历,否则体现不出双向链表的优势了。
10.在特定位置插入
oid DoubleNode::insert(int index,int data)
{
int length=getsize();
if(index<=0||index>length)
{
cout<<"index error"<<endl;
return;
}
Node *p = new Node;//插入节点
p->data=data; //赋值
if(index<=length/2)
{
Node *temp = head;
for(int i=0;i<index;i++)
{
temp = temp->next;
}
p->last = temp; //
p->next = temp->next;
temp->next->last = p;
temp->last->next = p;
temp->next = p;
}
else
{
Node *temp = tail;
for(int i=0;i<length-index+1;i++)
{
temp = temp->last;
}
p->last = temp->last;
temp->last->next = p;
temp->last = p;
p->next = temp;
}
}
同样是用了二分查找的部分思想
11.头插法
void DoubleNode::insert_first(int data)
{
Node *p = new Node;
p->data=data;
if(getsize()==0)
{
cout<<"an empty list"<<endl;
head = new Node;
head->last = nullptr;
head->next = p; //head链接p
p->last = head;
tail = new Node;
p->next = tail;
tail->last = p;
tail->next = nullptr;
}
else
{
p->next = head->next;
head->next->last = p;
p->last = head;
head->next = p;
}
}
判断链表是否为空,为空的处理是不一样的。
12.尾插法
void DoubleNode::insert_append(int data)
{
Node *p =new Node;
p->data=data;
if(getsize()==0)
{
cout<<"an empty list"<<endl;
head = new Node;
head->last = nullptr;
head->next = p; //head链接p
p->last = head;
tail = new Node;
p->next = tail;
tail->last = p;
tail->next = nullptr;
}
else
{
tail->last->next=p;
p->last = tail->last;
tail->last = p;
p->next = tail;
}
}
原理与头插法类似
13.删除指定元素
void DoubleNode::del(int index)
{
int length = getsize();
if(length==0)
{
cout<<"list is empty"<<endl;
return;
}
else if(index<=length/2)
{
Node *p = head;
for(int i=0;i<index;i++)
{
p = p->next;
}
p->last->next = p->next;
p->next->last = p->last;
delete p;
}
else if(index>length/2)
{
Node *p =tail;
for(int i=0;i<length-index+1;i++)
{
p=p->last;
}
p->last->next = p->next;
p->next->last = p->last;
}
}
其实删除和插入的原理是一样的。
14.头删法
void DoubleNode::delete_first()
{
int length = getsize();
if(length==0)
{
cout<<"list is empty"<<endl;
return;
}
Node * temp =head->next;
head->next->next->last = head; //跳过一个节点,也就是下下个节点的last是head;
head->next = head->next->next; //头结点的next指向后两个节点
delete temp;
temp = nullptr;
}
15.尾删法
void DoubleNode::delete_end()
{
int length = getsize();
if(length==0)
{
cout<<"list is empty"<<endl;
return;
}
Node *temp = tail->last;
tail->last->last->next = tail;
tail->last = tail->last->last;
delete temp;
}
总结
双向链表比单链表多了一个指针,也有更多需要考虑的点,但是通过亲自实现,也学到了很多的知识,对数据结构的掌握同样也更进一步了。