趣谈Linux操作系统学习笔记
综述
1.命令配合grep组合使用
如:ps -ef | grep "zsh" 这样就可以找到名称中含有zsh的进程了。

系统初始化
1. 0号进程和1号进程
0号进程不会通过fork和kernel_thread生成 其实是一个进程管理的工具,通过kernel_thread来创建一号进程。
分层的权限机制:
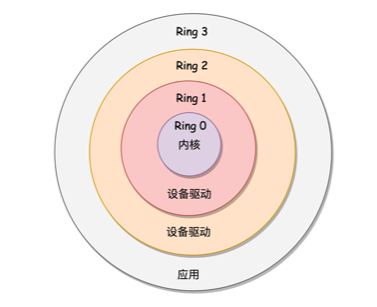
1号进程本质上则是一个文件,运行各种配置信息:
····
if (ramdisk_execute_command) {
ret = run_init_process(ramdisk_execute_command);
}
····
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
2.ramdisk 的作用
init 终于从内核到用户态了。一开始到用户态的是 ramdisk 的 init,后来会启动真正根文件系统上的 init,成为所有用户态进程的祖先。
init 程序是在文件系统上的,文件系统一定是在一个存储设备上的,例如硬盘。Linux 访问存储设备,要有驱动才能访问。如果存储系统数目很有限,那驱动可以直接放到内核里面。
ramdisk是为了防止要访问的东西越来越多,对其进行统一管理的根文件系统。
运行 ramdisk 上的 /init。等它运行完了就已经在用户态了。/init 这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk 上的 /init 会启动文件系统上的 init。
3.2号进程
用来管理内核态的所有进程。
4.系统的调用方式
讲述如何打开一个文件等操作。

5.软连接和硬链接
硬链接是通过索引节点进行的链接。在Linux中,多个文件指向同一个索引节点是允许的,像这样的链接就是硬链接。硬链接只能在同一文件系统中的文件之间进行链接,不能对目录进行创建。
如果删除硬链接对应的源文件,则硬链接文件仍然存在,而且保存了原有的内容,这样可以起到防止因为误操作而错误删除文件的作用。由于硬链接是有着相同 inode 号仅文件名不同的文件,因此,删除一个硬链接文件并不影响其他有相同 inode 号的文件。
link oldfile newfile
ln oldfile newfile
软链接(也叫符号链接)与硬链接不同,文件用户数据块中存放的内容是另一文件的路径名的指向。软链接就是一个普通文件,只是数据块内容有点特殊。软链接可对文件或目录创建。
软链接主要应用于以下两个方面:一是方便管理,例如可以把一个复杂路径下的文件链接到一个简单路径下方便用户访问;另一方面就是解决文件系统磁盘空间不足的情况。
例如某个文件文件系统空间已经用完了,但是现在必须在该文件系统下创建一个新的目录并存储大量的文件,那么可以把另一个剩余空间较多的文件系统中的目录链接到该文件系统中,这样就可以很好的解决空间不足问题。
删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接就变成了死链接。
ln -s old.file soft.link
ln -s old.dir soft.link.dir
进程和线程
1.进程调度
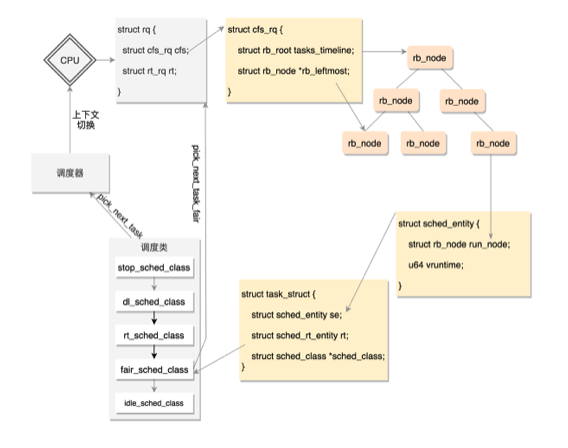
Linux进程调度是将进程指针存放在红黑树中
1.1.主动调度
这个片段可以看作写入块设备的一个典型场景。写入需要一段时间,这段时间用不上 CPU,还不如主动让给其他进程。
static void btrfs_wait_for_no_snapshoting_writes(struct btrfs_root *root)
{
......
do {
prepare_to_wait(&root->subv_writers->wait, &wait,
TASK_UNINTERRUPTIBLE);
writers = percpu_counter_sum(&root->subv_writers->counter);
if (writers)
schedule();
finish_wait(&root->subv_writers->wait, &wait);
} while (writers);
}
网络收发,数据库操作也有点类似主动调度。
1.2.抢占式调度
最常见的现象就是一个进程执行时间太长了,是时候切换到另一个进程了。
那怎么衡量一个进程的运行时间呢?在计算机里面有一个时钟,会过一段时间触发一次时钟中断,通知操作系统,时间又过去一个时钟周期,这是个很好的方式,可以查看是否是需要抢占的时间点。
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
......
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq);
calc_global_load_tick(rq);
......
}
这个函数先取出当前 CPU 的运行队列,然后得到这个队列上当前正在运行中的进程的 task_struct,然后调用这个 task_struct 的调度类的 task_tick 函数,顾名思义这个函数就是来处理时钟事件的。
- 用户态的抢占时机
对于用户态的进程来讲,从系统调用中返回的那个时刻,是一个被抢占的时机。
- 内核态的抢占时机
在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调用 preempt_disable() 关闭抢占,当再次打开的时候,就是一次内核态代码被抢占的机会。
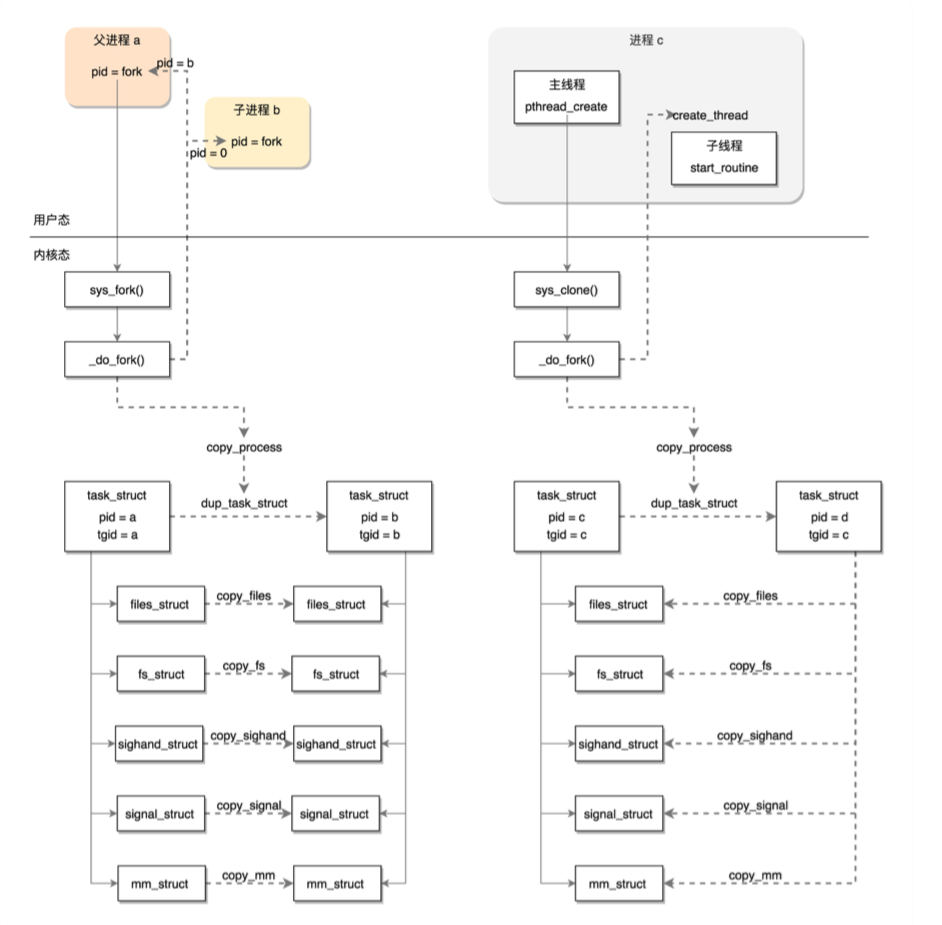
2.进程创建流程
第一步,复制进程结构。

static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
int retval;
struct task_struct *p;
......
p = dup_task_struct(current, node);
dup_task_struct 主要做了下面几件事情:
-
调用 alloc_task_struct_node 分配一个 task_struct 结构;
-
调用 alloc_thread_stack_node 来创建内核栈,这里面调用 __vmalloc_node_range 分配一个连续的 THREAD_SIZE 的内存空间,赋值给 task_struct 的 void *stack 成员变量;
-
调用 arch_dup_task_struct(struct task_struct *dst, struct task_struct *src),将 task_struct 进行复制,其实就是调用 memcpy;调用 setup_thread_stack 设置 thread_info。
copy_process:
retval = copy_creds(p, clone_flags);
轮到权限相关了,copy_creds 主要做了下面几件事情:
- 调用 prepare_creds,准备一个新的 struct cred *new。如何准备呢?其实还是从内存中分配一个新的 struct cred 结构,然后调用 memcpy 复制一份父进程的 cred;
- 接着 p->cred = p->real_cred = get_cred(new),将新进程的“我能操作谁”和“谁能操作我”两个权限都指向新的 cred。
重新设置进程运行统计量
p->utime = p->stime = p->gtime = 0;
p->start_time = ktime_get_ns();
p->real_start_time = ktime_get_boot_ns();
设置调度相关变量
retval = sched_fork(clone_flags, p);
sched_fork 主要做了下面几件事情:
-
调用 __sched_fork,在这里面将 on_rq 设为 0,初始化 sched_entity,将里面的 exec_start、sum_exec_runtime、prev_sum_exec_runtime、vruntime 都设为 0。你还记得吗,这几个变量涉及进程的实际运行时间和虚拟运行时间。是否到时间应该被调度了,就靠它们几个;
-
设置进程的状态 p->state = TASK_NEW;初始化优先级 prio、normal_prio、static_prio;
-
设置调度类,如果是普通进程,就设置为 p->sched_class = &fair_sched_class;调用调度类的 task_fork 函数,对于 CFS 来讲,就是调用 task_fork_fair。在这个函数里,先调用 update_curr,对于当前的进程进行统计量更新,然后把子进程和父进程的 vruntime 设成一样,最后调用 place_entity,初始化 sched_entity。这里有一个变量 sysctl_sched_child_runs_first,可以设置父进程和子进程谁先运行。如果设置了子进程先运行,即便两个进程的 vruntime 一样,也要把子进程的 sched_entity 放在前面,然后调用 resched_curr,标记当前运行的进程 TIF_NEED_RESCHED,也就是说,把父进程设置为应该被调度,这样下次调度的时候,父进程会被子进程抢占。
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);
唤醒新的进程,设置进程的状态,同时从队列中取出。
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
......
p->state = TASK_RUNNING;
......
activate_task(rq, p, ENQUEUE_NOCLOCK);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
......
}
3.创建线程
内存管理
1.Linux的段
分段机制:
段选择子和段内偏移量。段选择子就保存在咱们前面讲过的段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。
段表里面保存的是这个段的基地址、段的界限和特权等级等。虚拟地址中的段内偏移量应该位于 0 和段界限之间。如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
简单来说就是将内存分段管理。
分页机制:
对于物理内存,操作系统把它分成一块一块大小相同的页,这样更方便管理,例如有的内存页面长时间不用了,可以暂时写到硬盘上,称为换出。一旦需要的时候,再加载进来,叫做换入。
这样可以扩大可用物理内存的大小,提高物理内存的利用率。
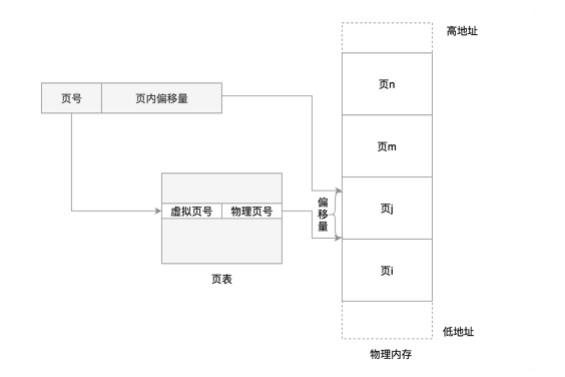
对页表再分页 可以实现节省空间的效果。
我们可以把内存管理系统精细化为下面三件事情:
第一,虚拟内存空间的管理,将虚拟内存分成大小相等的页;
第二,物理内存的管理,将物理内存分成大小相等的页;
第三,内存映射,将虚拟内存页和物理内存页映射起来,并且在内存紧张的时候可以换出到硬盘中。
exec读取ELF文件的时候,一方面是解析其中的二进制数据,一方面是建立虚拟内存映射。
2.内存模型与CPU访问
平坦内存模型
由于物理地址连续,页也是连续的,对于任何地址只需要除页号就能算出在哪一页。
x86的工作模式,CPU是通过总线访问内存的。
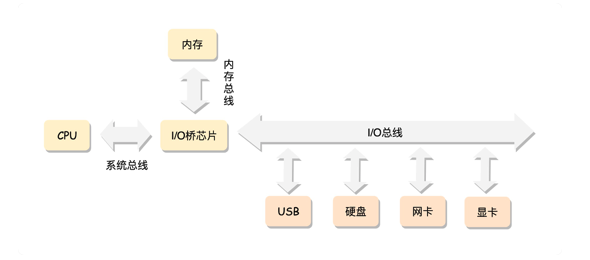
在这种模式下,CPU 也会有多个,在总线的一侧。所有的内存条组成一大片内存,在总线的另一侧,所有的 CPU 访问内存都要过总线,而且距离都是一样的,这种模式称为 SMP(Symmetric multiprocessing),即对称多处理器。
NUMA
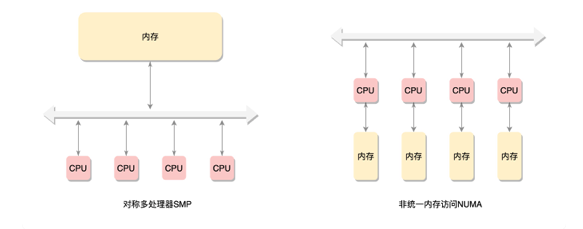
为了提高性能和可扩展性,后来有了一种更高级的模式,NUMA(Non-uniform memory access),非一致内存访问。在这种模式下,内存不是一整块。每个 CPU 都有自己的本地内存,CPU 访问本地内存不用过总线,因而速度要快很多,每个 CPU 和内存在一起,称为一个 NUMA 节点。
但是,在本地内存不足的情况下,每个 CPU 都可以去另外的 NUMA 节点申请内存,这个时候访问延时就会比较长。
这里需要指出的是,NUMA 往往是非连续内存模型。而非连续内存模型不一定就是 NUMA,有时候一大片内存的情况下,也会有物理内存地址不连续的情况。
文件系统
1.文件管理结构
树形结构,根目录->用户目录->目录->文件。
Linux 内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用。
2.硬盘存储
通过块的方式,将文件的内容分块存储。
ex2和ex3的实现
有点类似MySQL的B+树,分块存储,当文很大的时候,会有二次间接块来存放间接块的位置,间接块再指向数据块的位置,数据块则存放了真正的数据。
文件大小继续增长,还会有三次间接块。
ex4的Extents
Extents 可以用于存放连续的块,也就是说,我们可以把 128M 放在一个 Extents 里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了。
通过树形结构存储。
3.打开文件的过程
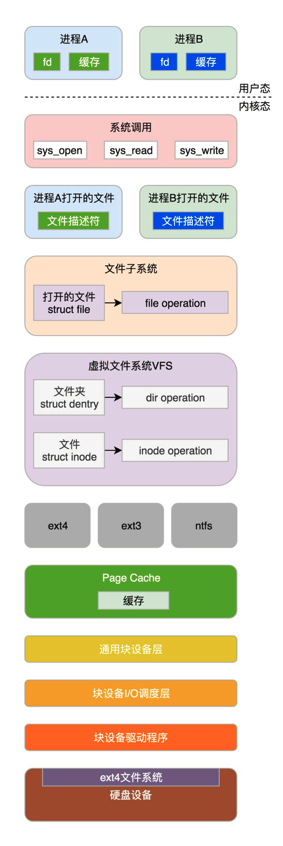
文件缓存机制略。
输入输出系统
1.设备分类
输入输出设备我们大致可以分为两类:块设备(Block Device)和字符设备(Character Device)。
块设备将信息存储在固定大小的块中,每个块都有自己的地址。硬盘就是常见的块设备。字符设备发送或接收的是字节流。而不用考虑任何块结构,没有办法寻址。鼠标就是常见的字符设备。
有的设备需要读取或者写入大量数据。如果所有过程都让 CPU 协调的话,就需要占用 CPU 大量的时间,
比方说,磁盘就是这样的。这种类型的设备需要支持 DMA 功能,也就是说,允许设备在 CPU 不参与的情况下,能够自行完成对内存的读写。
2.驱动程序
驱动程序主要是为了屏蔽设备控制器的差异。
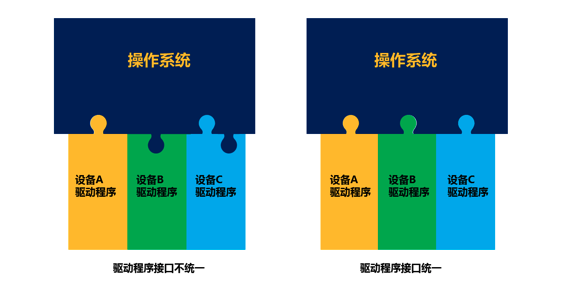
在 Linux 上面,如果一个新的设备从来没有加载过驱动,也需要安装驱动。
Linux 的驱动程序已经被写成和操作系统有标准接口的代码,可以看成一个标准的内核模块。在 Linux 里面,安装驱动程序,其实就是加载一个内核模块。
进程间通信
1.管道
ps -ef | grep 关键字 | awk '{print $2}' | xargs kill -9
其中的竖线就是匿名管道,将前一个命令的输出作为后一个命令的输入。
mkfifo hello
创建一个命名管道。
管道有读端和写端,写入数据则需要另一个进程去读取。
瀑布模型的开发流程效率比较低下,因为团队之间无法频繁地沟通。而且,管道的使用模式,也不适合进程间频繁地交换数据。
2.共享内存与信号量
操作系统拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了。
如果一个进程想要访问这一段共享内存,需要将这个内存加载到自己的虚拟地址空间的某个位置。
如果两个进程 attach 同一个共享内存,大家都往里面写东西,很有可能就冲突了。例如两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了。
所以,这里就需要一种保护机制,使得同一个共享的资源,同时只能被一个进程访问。在 System V IPC 进程间通信机制体系中,早就想好了应对办法,就是信号量(Semaphore)。因此,信号量和共享内存往往要配合使用。
信号量其实是一个计数器,主要用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
例如,你有 100 元钱,就可以将信号量设置为 100。其中 A 向你借 80 元,就会调用 P 操作,申请减去 80。
如果同时 B 向你借 50 元,但是 B 的 P 操作比 A 晚,那就没有办法,只好等待 A 归还钱的时候,B 的 P 操作才能成功。
之后,A 调用 V 操作,申请加上 30 元,也就是还给你 30 元,这个时候信号量有 50 元了,这时候 B 的 P 操作才能成功,才能借走这 50 元。
3.信号
信号可以在任何时候发送给某一进程,进程需要为这个信号配置信号处理函数。
当某个信号发生的时候,就默认执行这个函数就可以了。这就相当于咱们运维一个系统应急手册,当遇到什么情况,做什么事情,都事先准备好,出了事情照着做就可以了。
Signal Value Action Comment
──────────────────────────────────────────────────────────────────────
SIGHUP 1 Term Hangup detected on controlling terminal
or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
SIGKILL 9 Term Kill signal
SIGSEGV 11 Core Invalid memory reference
SIGPIPE 13 Term Broken pipe: write to pipe with no
readers
SIGALRM 14 Term Timer signal from alarm(2)
SIGTERM 15 Term Termination signal
SIGUSR1 30,10,16 Term User-defined signal 1
SIGUSR2 31,12,17 Term User-defined signal 2
……
4.小结
可以根据不同的通信需要,选择不同的模式。
管道,记住这是命令行中常用的模式,面试问到的话,不要忘了。
消息队列其实很少使用,因为有太多的用户级别的消息队列,功能更强大。
共享内存加信号量是常用的模式。这个需要牢记,常见到一些知名的以 C 语言开发的开源软件都会用到它。
信号更加常用,机制也比较复杂。
网络系统
1.socket的概念
两种网络协议模型,一种是 OSI 的标准七层模型,一种是业界标准的 TCP/IP 模型。
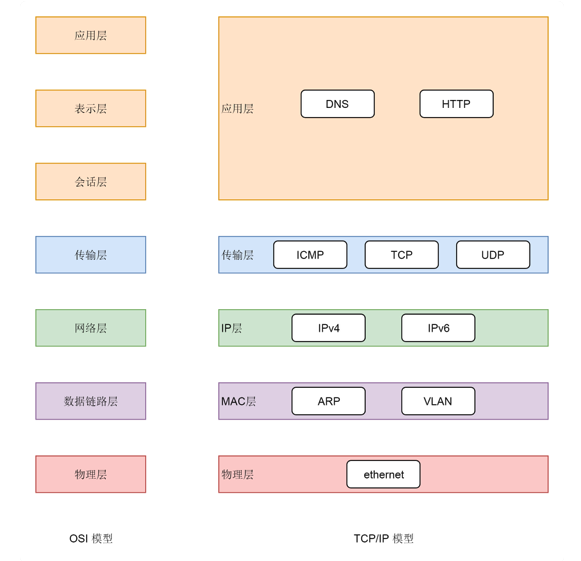
应用层和内核互通的机制,就是通过 Socket 系统调用。
所以经常有人会问,Socket 属于哪一层,其实它哪一层都不属于,它属于操作系统的概念,而非网络协议分层的概念。
只不过操作系统选择对于网络协议的实现模式是,二到四层的处理代码在内核里面,七层的处理代码让应用自己去做,两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是 Socket。
2.tcp和udp的区别
TCP 是面向连接的,UDP 是面向无连接的。
TCP 提供可靠交付,无差错、不丢失、不重复、并且按序到达;UDP 不提供可靠交付,不保证不丢失,不保证按顺序到达。
TCP 是面向字节流的,发送时发的是一个流,没头没尾;UDP 是面向数据报的,一个一个地发送。
TCP 是可以提供流量控制和拥塞控制的,既防止对端被压垮,也防止网络被压垮。
虚拟化
Linux一开始设计的时候没考虑到,后期会出现虚拟化技术。
1.完全虚拟化
这是一种“骗人”的方式。虚拟化软件会模拟假的 CPU、内存、网络、硬盘给到我,让我自我感觉良好,感觉自己终于又像个内核了。
2.硬件辅助虚拟化(Hardware-Assisted Virtualization)
对于虚拟机内核来讲,只要将标志位设为虚拟机状态,我们就可以直接在 CPU 上执行大部分的指令,不需要虚拟化软件在中间转述,除非遇到特别敏感的指令,才需要将标志位设为物理机内核态运行,这样大大提高了效率。
所以,安装虚拟机的时候,我们务必要将物理 CPU 的这个标志位打开。想知道是否打开,对于 Intel,你可以查看 grep “vmx” /proc/cpuinfo;对于 AMD,你可以查看 grep “svm” /proc/cpuinfo。
3.半虚拟化(Paravirtualization)
另外就是访问网络或者硬盘的时候,为了取得更高的性能,也需要让虚拟机内核加载特殊的驱动,也是让虚拟机内核从代码层面就重新定位自己的身份,不能像访问物理机一样访问网络或者硬盘,而是用一种特殊的方式。
我知道我不是物理机内核,我知道我是虚拟机,我没那么高的权限,我很可能和很多虚拟机共享物理资源,所以我要学会排队,我写硬盘其实写的是一个物理机上的文件,那我的写文件的缓存方式是不是可以变一下。
我发送网络包,根本就不是发给真正的网络设备,而是给虚拟的设备,我可不可以直接在内存里面拷贝给它,等等等等。
容器技术
和虚拟化技术相比,就是分出一小部分资源,专门跑一个进程。
容器带来了两个好处,封装和标准。
优势
- 持续集成
不存在“你这里跑的起来,他那里跑不起来的情况”
- 弹性伸缩
有了容器就方便多了,只要在每台机器上 docker run 一下就搞定了。
- 跨云迁移
等哪天想用另一个云了,不用怕应用迁移不走,只要在另外一个云上 docker run 一下就解决了。